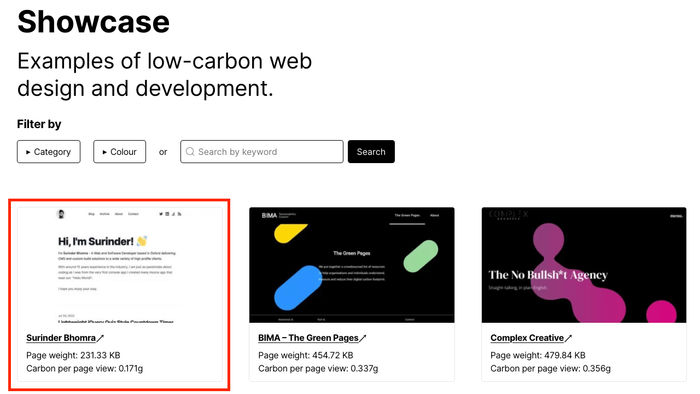
If you haven't noticed (and I hope you have), back in June I finally released an update to my website to look more pleasing to the eye. This has been a long time coming after being on the back-burner for a few years.
Embarrassingly, I’ve always stated in my many year in reviews that I planned on redeveloping this site over the next coming year, but never came to fruition. This is partly down to time and deciding to make content a priority. If I’m honest, it’s mostly down to lacking the skills and patience in carrying out the front-end development work.
Thankfully, I managed to knuckle down and decided to become acquainted and learnt enough about HTML and CSS to get the site where it currently stands, with the help of Tailwind CSS and an open-source base template to act as a good starting point for a novice front-end developer.
Tailwind CSS
Very early on, I knew the only hope I had to give this site a new look was to use a front-end framework like Tailwind CSS, requiring a minimal learning curve to produce quick results. It’s definitely not a front-end framework to be sniffed at as more than 260000 developers have used it for their design system. So it’s a framework that is here to stay - a worthwhile investment to learn.
Tailwind CSS is predominantly a CSS framework consisting of predefined classes to build websites directly within the markup without having to write a single line of custom CSS.
As you’re styling directly within the markup, at first glance it can be overwhelming, especially where multiple classes need to be declared on a single HTML block. A vast difference when compared to the cleanliness of builds carried out by the very skilful team from where I work.
It’s a small trade-off in an otherwise solid framework that gives substantial benefits in productivity. Primarily because Tailwind CSS classes aren’t very specific and gives a high level of customisability without you having to concoct CSS styles.
Even though there are many utility classes to get acquainted with, once you have an understanding of the core concepts, front-end builds become less of an uphill battle. Through rebuilding my site, I managed to quite quickly get familiarity with creating different layouts based on viewport size and modifying margins and padding.
I found it to be a very modular and component-driven framework, helping avoid repetition. There are UI kits on the market that give good examples of the power of Tailwind CSS that you can use to help speed up development:
Using Tailwind CSS took away my fear of front-end development without having to think about Bootstrap, BEM, SASS mix-ins, custom utility classes, purge processing, etc.
Base Template
I gave myself a 3-week target (not full-time) to get the new site released and this couldn't have been done without getting a head start from a base theme. I found an open-source template built by Timothy Lin on Tailwind Awesome website that suited my key requirements:
- Clean
- Simple
- Elegant
- Maintainable
- Easily customisable
Another developer by the name of Leo, developed another variation of this already great template where I felt it met my requirements down to a tee.
Even though the template code-base used was developed in Next.js, this did not matter as I could easily migrate the Tailwind markup into my Gatsby JS project. Getting Tailwind set up initially for Gatsby took a little tinkering to get right and to ensure the generated CSS footprint was kept relatively small.
As you can see from the new site build, I was able to make further modifications to suit my requirements. This in itself is a testament to the original template build quality and the power of Tailwind CSS.
Improvements
As well as changing the look of my site, I thought it would be an opportune time to make a few other small enhancements.
Google Ads
Removing Google Ads had been on the forefront of my mind ever since I moved over to Netlify to host my website. Previously, it was a way to contribute to the yearly hosting cost. Now, this is no longer of any relevance (as I'm on the free Netlify free hosting plan), especially when weighing the importance of a meagre monetary return over improving the overall website look and load times of the site.
In its place, I have a Buy Me A Coffee profile for those who would like to support the content I write.
Updated Version of Gatsby JS
It seemed natural to upgrade the version of Gatsby JS from version 2 to 4 during the reworking of my site to keep up-to-date with the latest changes and remove any deprecated code.
Upgrading from version 2 to 4 took a little longer than I'd hoped as other elements required updating such as Node and NPM packages. This resulted in a lot of breaking changes within my code-base that I had to rectify.
The process was arduous but worth doing as I found site builds in Netlify reduced significantly.
Gatsby Build Caching
I briefly spoke about improved Netlify build times (above) due to efficiencies in code changes relating to upgrading to Gatsby 4. There is one more quiver to my bow to aid further build efficiencies and that is by installing the netlify-plugin-gatsby-cache plugin within Netlify - one-click install.
I highly recommend everyone who has a Gatsby site install this plugin as it instantly reduces build times. For a website like my own that houses over 300 posts the build minutes do start to add up.
Features Yet To Be Implemented
Even though the new version of my site is live, there are features I still plan on implementing.
Algolia Site Search
As part of getting a new version of my site released in such a short period, I had to focus on the core areas and everything else was secondary. One of the features that didn’t make the cut was the site search using Algolia.
I do plan on reinstating the site search feature at some point as I found it helpful for me to search through my older posts and surprisingly (based on the stats) visitors to the site also made use of it.
Short-Form Content
I like the idea of posting smaller pieces of content that doesn't have to result in very lengthy written blog posts. Not sure what I will call this new section. There are only two names that come to mind: "Short-form" or "Bytesize". It could consist of the following types of content:
- Small, concise code snippets.
- Links to content I found useful online that could be useful in certain technical use-cases.
- Book recommendations.
- Quotes.
- Thoughts on news articles - John Gruber style!
At one point, I wrote blog posts I categorised as Quick Tips, till this date consists of a mere four blog posts that I never added to. I think the naming of this category wasn't quite right.
I see this section functioning in a similar fashion to Marco Heine's Today I Learned.
My Bookmarks
I like the idea of having single page with a bunch of links to useful sites I keep going back to. It could be sites that you have never come across before, making all the more reason to share these links.
Closing Thoughts
I normally find a full-site rebuild quite trying at times. This time was different and there were two reasons for this.
Firstly, I've already built the site in Gatsby JS and involved minimal code changes, even when taking into consideration the changes needed to update to version 4. Secondly, using Tailwind CSS as a front-end framework was a very rewarding experience especially when page builds come to fruition in such a quick turnaround.
I hope you find the new design is more aesthetically pleasing and makes reading through blog posts a more enjoyable experience.