When Kentico offered the option to build websites using MVC, I was one of the many developers who jumped at the chance to utilise the new programming model. I've been building websites using the MVC programming model ever since it was first made available in Kentico 7 and with each version, the MVC implementation just got better and better. So much so, I even built my very own website (currently in Kentico 8) in MVC.
MVC in Kentico has always been a bit of a hybrid being in the sense that it wasn't true MVC to the core, which is to be expected when you have to accommodate vast array of features the Kentico platform offers. Luckily for us Kentico 9 has wholeheartedly embraced MVC with open arms and things can only get better with subsequent versions.
I have listed a few observations I thought would be good to write about from my initial experience of using MVC in Kentico 9 whilst working on a client project. I will be talking (very high level) about the changes from previous versions of Kentico MVC as well as the new development approaches for Kentico 9.
1) Goodbye "Pages", Hello "Content-only Pages" Page Types
"Content-only pages" is a new addition to Kentico 9 and is another form of Page Type, with its primary job (as the name suggests) to store content. The main difference between "Pages" and "Content-only Pages", is:
- Aren't based on Page Templates.
- Provides a simplified interface when managing content.
- Does not have a presentation URL. URL patterns now need to be specified which handles the presentation to the MVC site via routing.
- Lacks the ability to create many Page Aliases.
"Content-only pages" is a requirement to developing MVC sites in Kentico 9. Overall, I actually found "Content-only pages" quite restrictive and useful key page properties are no longer available, such as the URLs and Navigation tabs. I really do wish that these features were left in.

I will be talking more about the removal of the URLs in my next point, the missing Navigation property is easier to get around. I created a base content page called "Kentico Core Content" that contained all the fields that you would normally find under Navigation properties and inherited this page type on all my content-only pages, such as Articles. You'll then have to just make the customisations to inherit these fields at code level. Easy!
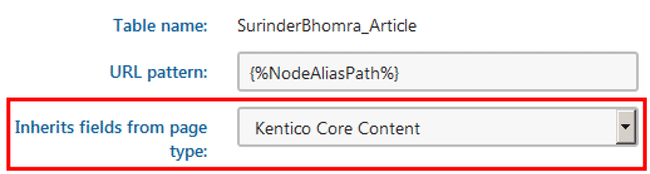
2) No Document Aliases
There's no option to allow the site administrator to add multiple document aliases for a page. This alone was nearly a deal breaker for me and was tempted to either go down Portal or ASPX templates route. The ability to create multiple document aliases in the URLs section is very powerful feature, especially if you plan on adding 301 redirects.
To get around this excluded feature, you will either have to use URL Rewriting at web.config level or add additional routes at controller level to carry out all specific page redirects.
So before deciding whether to choose the MVC approach, ask yourself if this is pressing feature for you and your client.
3) Separation of the CMS and Presentation Layer
Kentico 8 stepped up the MVC integration by allowing the developer to build their sites using MVC through the CMSApp_MVC project. This created a basic form of separation at project level that was much better suited compared to mixing key MVC components (Controllers/Models/Views) into what is a Web Form powered site in it's infancy in Kentico 7.
Now there is complete separation between the CMS Admin and Presentation layer (or MVC site). Since the CMSApp_MVC approach has been made obselete in Kentico 9, you now have the full ability to create an MVC site as you would do normally in a non-Kentico web application. The only way Kentico and your MVC website can talk to one another is through a Web Farm configuration.
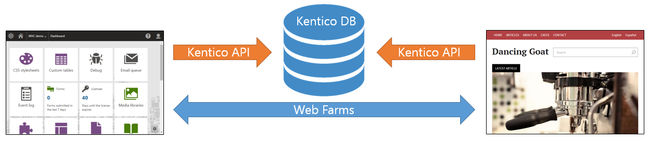
I personally love this setup. My website can be kept light as possible and still harness the power of what Kentico has to offer through using conventional API calls from the Kentico library. I can tell you this for sure, the website itself performs better than ever and no one can tell what CMS is powering the site. Good for security.
4) Licensing and Environment Setup
Due to the need for Web Farm setup to allow syncronisation of content between the CMS and MVC site, the licensing requirements have changed. Based upon how you want to setup your separate sites, Kentico provides different licensing approaches, which pretty much covers all scenarios.
My preferred setup is to run the Kentico and the MVC application under two different sites, on separate domains. Again, my reasoning comes down to catering for that additional level of security where the management of your site is on a sub-domain and not so obvious where the administration area resides. In this case, two licenses will be required. For example:
You will get a free license for the Kentico site as long as the subdomain is "admin".
The only sad part (for me personally) is that Kentico CMS Free Edition license does not allow for MVC websites. I really do hope that this changes at some point. I'd love to utilise full Kentico 9 MVC on future personal projects that are currently on the free edition. Otherwise they will forever be stuck in version 8.2.
5) Page Templates
The ability to use Page Templates alongside standard page types is still available within the Kentico interface, but you can only develop an MVC site this way by creating a (now obsolete) "CMSApp_MVC" project. Kentico 9 MVC is still fully backwards compatible with this approach.
6) Retrieving Content In MVC Controllers
In Kentico 8, a controller acted as the code-behind to your Page Template where you could get all the information about a current page by calling DocumentContext.CurrentDocument. In Kentico 9, this is no longer the case and it is recommended content should be retrieved using its auto-generated code. I generally don't go down the route of using the auto-generated code. I instead like to create my own custom methods so I have the freedom to pull out the exact data my data needs by passing the Node Alias Path into my control from the URL route patten. Personal preference.
7) Friendly URL's Should Include A Node ID
Kentico recommends all page URL's should consist of NodeID and Page alias, to ensure optimum search engine optimisation on the event the page alias of pages changes on the live site. Kentico's documentation states:
Typically, a page alias will be part of a macro expression that makes up a URL pattern in content only page types. For example, a URL pattern can be specified like this /Articles/{%NodeID%}/{%NodeAlias%}. Where {%NodeAlias%} accesses the page alias.
I've gone down the route of creating a custom route contraint in my MVC project, to allow me to retrieve TreeNode for the current document via HttpContext just from passing the Node Alias only. I could go into more detail, but this is probably best suited for another blog post.
Conclusion
The MVC integration in Kentico is like a fine wine. It gets better and better every year (in this case release) and they should be congratulated for undertaking such a humongous task. Would I choose it over Portal or ASPX pages for every project? Probably not, because I can see clients expecting functionality that is not quite present in an MVC installation as of yet.
I do like the freedom MVC gives me whilst harnessing the power of Kentico and it works great on those projects that require maximum flexibility and the seperation of code-levels allows me to do that. In addition, if my site requires scaling, I can easily move it to Azure. I am very much looking forward to what Kentico has in store for feature releases.
If there is anything I have listed in my initial observation that are incorrect, please leave a comment and I will update this post.