I stated in my last post that when I got better knowledge of using Google Checkout, I will show a full example on how to implement Google’s payment provider.
What I wanted to achieve within my own Google Checkout implementation was the ability to ensure I was retrieving sufficient information from the payment provider. So the transaction data stored within my own database would match exactly what is happening within Google. For example, if a payment was accepted/declined some internal processes need to be carried out. The best way of achieving this was by using a call-back page to process notifications from Google synchronously.
Before we get into the call-back code, we need to login to our Google Checkout account as a merchant and carry out some basic configuration setup. My example’s will be based on a sandbox environment.
Google Account Setup
Integration (Settings > Integration)
The Integration configuration is the most important page since it contains the basis to how we would like Google Checkout to work.

As you can see, we have specified a call-back URL that will point to a page in our site. The call-back page is what Google uses to let our site know what’s happening with our transactions and if required, we can create our own internal actions to deal with events that are thrown to us. I have set the notifications to be sent in XML format.
Next, we want to ensure the correct API version is used. Issues are bound to occur is the incorrect version is selected. In this case, I am using the most recent API version: 2.5.
I have unselected Notification Filtering because we want to receive all types of notifications. Google Checkout document states:
“Google Checkout responds with a <charge-amount-notification> synchronously after a charge-order request. If you have not selected the option to only receive new order notifications, authorization amount notifications and order state change notifications, Google Checkout will also send you a charge-amount-notification anytime an order has been charged.”
We want to receive a “charge amount notification” to allow us to know if the transaction was charged successfully. This is an actual confirmation to state we have received the money. We shouldn’t assume anything until this is received.
Preferences (Settings > Preferences)

I have setup our order processing to automatically authorise the buyers card for an order. You might be thinking: “This is a bit of manual process…” and you’d be right. If we selected the second option to automatically authorise and charge the buyers card, this would leave a big hole in setting up our internal website processes. By authorising a buyers card gives us more flexibility on how to handle the transaction.
It’s not compulsory for the email option to be selected.
Other Setup
You should be good to go on starting to mess around with implementing your site with Google Checkout. What I haven’t covered is the financial settings such as adding Banking information. This should be a straight-forward process. My main aim is to make sure the basics of Google Merchant account setup is complete.
One really useful page that will help you with investigating problematic transactions is the “Integration Console” (Tools > Integration Console). Generally, this should be empty but any issues will be logged here. This has helped me over the course of integrating Google Checkout in my site.
Call-back Page
Ok. We have Google Merchant Account setup. Now we need to concentrate on our call-back page. My call-back page is based on a customer purchasing a News subscription. We are going to capture all the data Google sends us (excluding refunds) and store them in our own database.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.IO;
using GCheckout;
using GCheckout.AutoGen;
using GCheckout.Util;
using GCheckout.OrderProcessing;
using System.Xml;
public partial class Pay_GCheckout : System.Web.UI.Page
{
public string SerialNumber = "";
void Page_Load(Object sender, EventArgs e)
{
// Extract the XML from the request.
Stream RequestStream = Request.InputStream;
StreamReader RequestStreamReader = new StreamReader(RequestStream);
string RequestXml = RequestStreamReader.ReadToEnd();
RequestStream.Close();
// Act on the XML.
switch (EncodeHelper.GetTopElement(RequestXml))
{
case "new-order-notification":
NewOrderNotification N1 = (NewOrderNotification)EncodeHelper.Deserialize(RequestXml, typeof(NewOrderNotification));
SerialNumber = N1.serialnumber;
string OrderNumber1 = N1.googleordernumber;
string ShipToName = N1.buyershippingaddress.contactname;
string ShipToAddress1 = N1.buyershippingaddress.address1;
string ShipToAddress2 = N1.buyershippingaddress.address2;
string ShipToCity = N1.buyershippingaddress.city;
string ShipToState = N1.buyershippingaddress.region;
string ShipToZip = N1.buyershippingaddress.postalcode;
CustomerSubscription cs = new CustomerSubscription();
cs.TransactionNumber = OrderNumber1;
cs.Address1 = ShipToAddress1;
cs.Address2 = ShipToAddress2;
cs.Address3 = ShipToCity;
cs.Region = ShipToState;
cs.PostCode = ShipToZip;
cs.TransactionType = CustomerSubscription.TransTypeOnline;
cs.FinancialOrderState = N1.ordersummary.financialorderstate.ToString();
foreach (Item ThisItem in N1.shoppingcart.items)
{
string Name = ThisItem.itemname;
int Quantity = ThisItem.quantity;
decimal Price = ThisItem.unitprice.Value;
}
if (N1.shoppingcart.merchantprivatedata != null && N1.shoppingcart.merchantprivatedata.Any != null && N1.shoppingcart.merchantprivatedata.Any.Length > 0)
{
foreach (XmlNode node in N1.shoppingcart.merchantprivatedata.Any)
{
if (node.LocalName.Trim() == "customer-id")
{
cs.CustomerID = int.Parse(node.InnerText);
}
if (node.LocalName.Trim() == "subscription-id")
{
cs.SubscriptionID = int.Parse(node.InnerText);
}
}
}
CustomerSubscription.AddOnlineSubscription(cs);
break;
case "risk-information-notification":
RiskInformationNotification N2 = (RiskInformationNotification)EncodeHelper.Deserialize(RequestXml, typeof(RiskInformationNotification));
// This notification tells us that Google has authorized the order and it has passed the fraud check.
// Use the data below to determine if you want to accept the order, then start processing it.
SerialNumber = N2.serialnumber;
string OrderNumber2 = N2.googleordernumber;
string AVS = N2.riskinformation.avsresponse;
string CVN = N2.riskinformation.cvnresponse;
bool SellerProtection = N2.riskinformation.eligibleforprotection;
break;
case "order-state-change-notification":
OrderStateChangeNotification N3 = (OrderStateChangeNotification)EncodeHelper.Deserialize(RequestXml, typeof(OrderStateChangeNotification));
// The order has changed either financial or fulfillment state in Google's system.
SerialNumber = N3.serialnumber;
string OrderNumber3 = N3.googleordernumber;
string NewFinanceState = N3.newfinancialorderstate.ToString();
string NewFulfillmentState = N3.newfulfillmentorderstate.ToString();
string PrevFinanceState = N3.previousfinancialorderstate.ToString();
string PrevFulfillmentState = N3.previousfulfillmentorderstate.ToString();
break;
case "charge-amount-notification":
ChargeAmountNotification N4 = (ChargeAmountNotification)EncodeHelper.Deserialize(RequestXml, typeof(ChargeAmountNotification));
// Google has successfully charged the customer's credit card.
SerialNumber = N4.serialnumber;
string OrderNumber4 = N4.googleordernumber;
decimal ChargedAmount = N4.latestchargeamount.Value;
int customerID = 0;
if (N4.ordersummary.shoppingcart.merchantprivatedata != null && N4.ordersummary.shoppingcart.merchantprivatedata.Any != null && N4.ordersummary.shoppingcart.merchantprivatedata.Any.Length > 0)
{
foreach (XmlNode node in N4.ordersummary.shoppingcart.merchantprivatedata.Any)
{
if (node.LocalName.Trim() == "customer-id")
{
customerID = int.Parse(node.InnerText);
}
}
}
if (N4.ordersummary.financialorderstate == FinancialOrderState.CHARGED)
{
CustomerSubscription.UpdateFinancialOrderState(OrderNumber4, N4.ordersummary.financialorderstate.ToString());
//Make user paid member
CustomerHelper.UpgradeCustomerToPaid(customerID);
}
break;
case "refund-amount-notification":
RefundAmountNotification N5 = (RefundAmountNotification)EncodeHelper.Deserialize(RequestXml, typeof(RefundAmountNotification));
// Google has successfully refunded the customer's credit card.
SerialNumber = N5.serialnumber;
string OrderNumber5 = N5.googleordernumber;
decimal RefundedAmount = N5.latestrefundamount.Value;
break;
case "chargeback-amount-notification":
ChargebackAmountNotification N6 = (ChargebackAmountNotification)EncodeHelper.Deserialize(RequestXml, typeof(ChargebackAmountNotification));
// A customer initiated a chargeback with his credit card company to get her money back.
SerialNumber = N6.serialnumber;
string OrderNumber6 = N6.googleordernumber;
decimal ChargebackAmount = N6.latestchargebackamount.Value;
break;
case "authorization-amount-notification":
AuthorizationAmountNotification N7 = (AuthorizationAmountNotification)EncodeHelper.Deserialize(RequestXml, typeof(AuthorizationAmountNotification));
SerialNumber = N7.serialnumber;
string OrderNumber7 = N7.googleordernumber;
// Charge Order If Chargeable
if (N7.ordersummary.financialorderstate == FinancialOrderState.CHARGEABLE)
{
GCheckout.OrderProcessing.ChargeOrderRequest chargeReq = new GCheckout.OrderProcessing.ChargeOrderRequest(OrderNumber7);
GCheckoutResponse oneGCheckoutResponse = chargeReq.Send();
}
CustomerSubscription.UpdateFinancialOrderState(OrderNumber7, N7.ordersummary.financialorderstate.ToString());
break;
default:
break;
}
}
}
N.B: The code snippet (above) is shown purely as a simple example for you to build on. It is based on the “notification_handshake.aspx” sample code that is downloadable here.
So what’s going on here? Well the events are processed in the following order:
-
“new-order-notification” - A new order has been received. Details of the News Subscription along with the customer who ordered it will be stored in our database.
-
“authorization-amount-notification” - Google tells us that the amount has successfully be authorised. If the order state is “chargeable”, we can go ahead charge the order and update the order state. The customer order state will consist of the following statuses: Cancelled, Chargeable, Charged, Charging, Payment Declined and Reviewing. I think it’s a good to store this information because it will allow a site administrator to view statuses of all orders and act on them, if needed.
-
“charge-amount-notification” – Google verifies the order was successful. If the order state is marked as charged, the customer will be upgraded to a paid News Subscriber.
Outcome
You have successfully setup Google Checkout payment with basic notifications. If you already have Google Checkout code in place where a user can add one or more items to the shopping cart this code can stay. All you need to do is carry out the changes described in this post.

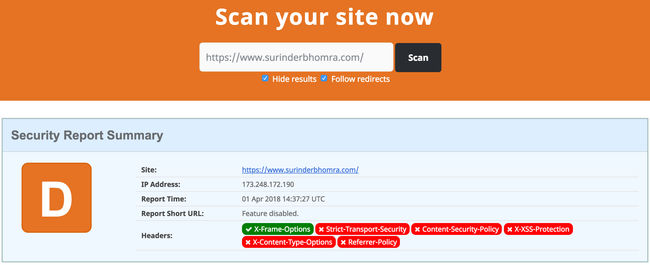
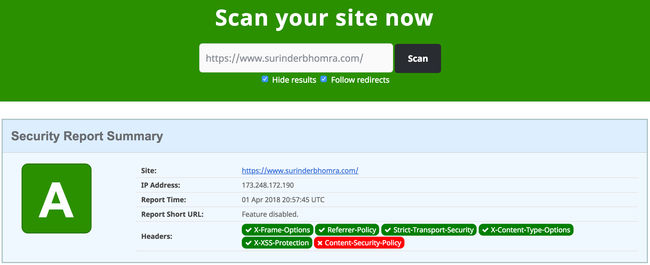
 When working as a programmer, it's really easy to continue coding in the same manner you have done since you picked up a language and made your first program.
When working as a programmer, it's really easy to continue coding in the same manner you have done since you picked up a language and made your first program.







