I've written some code that outputs images using Instagram's Developer API. The code can either output images based on a user's profile or via search term.
As you may already know, in order to get any form of information from any external API an access token is required. Before we dive into some code, the first thing that we need to do is register ourselves as an Instagram Developer by going to: http://instagram.com/developer/.
Next, we need to register a new client specifically for our intended use. In my case, all I want to do is to get all image information from my own Instagram profile.
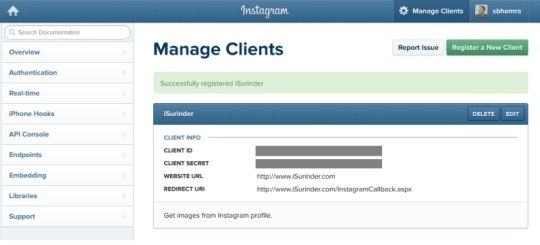
Here, you will be supplied with Client ID and Client Secret codes. But most importantly, you will need to set an OAuth Redirect URL (or Callback URL) for user's to authenticate your application.
The strange thing I've noticed about the Instagram API is that a callback page is a compulsory requirement. Even if you are planning on carrying out something as simple as listing some images from your own profile where a public users intervention is not required.
I'm not interested in their images, I'm interested in my own. I hope Instagram changes this soon. If Twitter can allow you to retrieve tweets by simply registering your application, why can't Instagram?
From what I've read on Instagram's Google Group's is that an access token needs to only be generated once and they don't expire. But of course Instagram have stated:
"These tokens are unique to a user and should be stored securely. Access tokens may expire at any time in the future."
Just make sure you have some fail safe's in your code that carries out the re-authentication process within your application on the event access token has expired. In my own implementation, I've kept the callback page secret and new access token requests can be made within an Administration interface.
So lets get to the code.
Step 1: Authentication Request Classes
These strongly-typed classes mirror the exact structure of the JSON returned from our authentication request. Even though we only require the "access_token" property, I've added additional information, such as details on the Instagram user making the request.
public class AuthToken
{
[JsonProperty("access_token")]
public string AccessToken { get; set; }
[JsonProperty("user")]
public InstagramUser User { get; set; }
}
public class InstagramUser
{
[JsonProperty("id")]
public string ID { get; set; }
[JsonProperty("username")]
public string Username { get; set; }
[JsonProperty("full_name")]
public string FullName { get; set; }
[JsonProperty("profile_picture")]
public string ProfilePicture { get; set; }
}
It's worth noting at this point that I'm using Newtonsoft.Json framework.
Step 2: Callback Page
protected void Page_Load(object sender, EventArgs e)
{
if (!String.IsNullOrEmpty(Request["code"]) && !Page.IsPostBack)
{
try
{
string code = Request["code"].ToString();
NameValueCollection parameters = new NameValueCollection();
parameters.Add("client_id", ConfigurationManager.AppSettings["instagram.clientid"].ToString());
parameters.Add("client_secret", ConfigurationManager.AppSettings["instagram.clientsecret"].ToString());
parameters.Add("grant_type", "authorization_code");
parameters.Add("redirect_uri", ConfigurationManager.AppSettings["instagram.redirecturi"].ToString());
parameters.Add("code", code);
WebClient client = new WebClient();
var result = client.UploadValues("https://api.instagram.com/oauth/access_token", "POST", parameters);
var response = System.Text.Encoding.Default.GetString(result);
var jsResult = JsonConvert.DeserializeObject(response);
//Store Access token in database
InstagramAPI.StoreAccessToken(jsResult.AccessToken);
Response.Redirect("/CallbackSummary.aspx?status=success", false);
}
catch (Exception ex)
{
EventLogProvider.LogException("Instagram - Generate Authentication Key", "INSTAGRAM", ex);
Response.Redirect("/CallbackSummary.aspx?status=error");
}
}
}
As you can see, I'm redirecting the user to a "CallbackSummary" page to show if the authentication request was either a success or failure. (Remember, the page is secured within my own Administration interface.)
If the request is successful, the access token is stored.
Step 3: Request Callback Page
The last piece of the puzzle is to actually request our callback page by authorizing ourselves via Instagram API. In this case, I just have a simple page with the following mark up:
<p>If Instagram fails to output images to the page, this maybe because a new Authorisation key needs to be generated.</p>
<p>To generate a new key, press the button below and follow the required steps.</p>
<a onclick="window.open('https://api.instagram.com/oauth/authorize/?client_id=<%=ConfigurationManager.AppSettings["instagram.clientid"].ToString() %>&redirect_uri=<%=ConfigurationManager.AppSettings["instagram.redirecturi"].ToString() %>&response_type=code', 'newwindow', config='height=476,width=641,toolbar=no, menubar=no, scrollbars=no, resizable=no,location=no,directories=no, status=no'); return false;" href="#" target="_parent">Generate</a>
If all goes to plan, you should have successfully recieved the access token.
I will post more Instagram code in future posts.

 When working as a programmer, it's really easy to continue coding in the same manner you have done since you picked up a language and made your first program.
When working as a programmer, it's really easy to continue coding in the same manner you have done since you picked up a language and made your first program.