ActiveCampaign is a comprehensive marketing tool that helps businesses automate their email marketing strategies and create targeted campaigns. If the tracking code is used, visitors can be tracked to understand how they interact with your content and curate targeted email campaigns for them.
I recently registered for a free account to test the waters in converting readers of my blog posts into subscribers to create a list of contacts that I could use to send emails to when I have published new content. For this website, I thought I'd create a Contact Form that will serve the purpose of allowing a user to submit a query as well as being added to a mailing list in the process.
ActiveCampaign provides all the tools to easily create a form providing multiple integration options, such as:
- Simple JavaScript embed
- Full embed with generated HTML and CSS
- Link to form
- WordPress
- Facebook
As great as these out-of-the-box options are, we have no control over how our form should look or function within our website. For my use, the Contact Form should utilise custom markup, styling, validation and submission process.
Step 1: Creating A Form
The first step is to create our form within ActiveCampaign using the form builder. This can be found by navigating to Website > Forms section. When the "Create a form" button is clicked, a popup will appear that will give us options on the type of form we would like to create. Select "Inline Form" and the contact list you would like the form to send the registrations to.
My form is built up based on the following fields:
- Full Name (Standard Field)
- Email
- Description (Account Field)
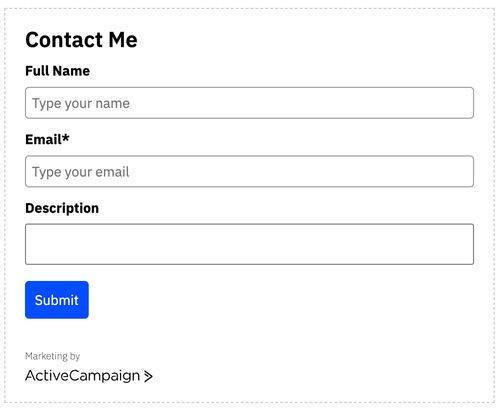
As we will be creating a custom-built form later, we don't need to worry about anything from a copy perspective, such as the heading, field labels or placeholder text.
Next, we need to click on the "Integrate" button on the top right and then the "Save and exit" button. We are skipping the form integration step as this is of no use to us.
Step 2: Key Areas of An ActiveCampaign Form
There are two key areas of an ActiveCampaign form we will need to acquire for our custom form to function:
- Post URL
- Form Fields
To get this information, we need to view the HTML code of our ActiveCampaign Contact form. This can be done by going back to the forms section (Website > Forms section) and selecting "Preview", which will open up our form in a new window to view.
In the preview window, open up your browser Web Inspector and inspect the form markup. Web Inspector has to be used rather than the conventional "View Page Source" as the form is rendered client-side.
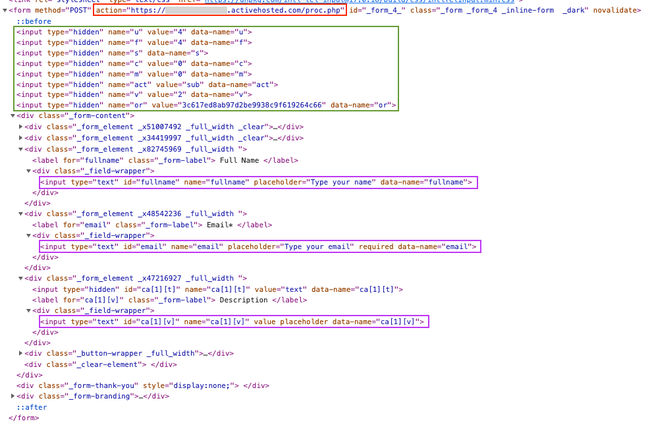
Post URL
The <form /> tag contains a POST action (highlighted in red) that is in the following format: https://myaccount.activehosted.com/proc.php. This URL will be needed for our custom-built form to allow us to send values to ActiveCampaign.
Form Fields
An ActiveCampaign form consists of hidden fields (highlighted in green) and traditional input fields (highlighted in purple) based on the structure of the form we created. We need to take note of the attribute names and values when we make requests from our custom form.
Step 3: Build Custom Form
Now that we have the key building blocks for what an ActiveCampaign form uses, we can get to the good part and delve straight into the code.
import React, { useState } from 'react';
import { useForm } from "react-hook-form";
export function App(props) {
const { register, handleSubmit, formState: { errors } } = useForm();
const [state, setState] = useState({
isSubmitted: false,
isError: false
});
const onSubmit = (data) => {
const formData = new FormData();
// Hidden field key/values.
formData.append("u", "4");
formData.append("f", "4");
formData.append("s", "s");
formData.append("c", "0");
formData.append("m", "0");
formData.append("act", "sub");
formData.append("v", "2");
formData.append("or", "c0c3bf12af7fa3ad55cceb047972db9");
// Form field key/values.
formData.append("fullname", data.fullname);
formData.append("email", data.email);
formData.append("ca[1][v]", data.contactmessage);
// Pass FormData values into a POST request to ActiveCampaign.
// Mark form submission successful, otherwise return error state.
fetch('https://myaccount.activehosted.com/proc.php', {
method: 'POST',
body: formData,
mode: 'no-cors',
})
.then(response => {
setState({
isSubmitted: true,
});
})
.catch(err => {
setState({
isError: true,
});
});
}
return (
<div>
{!state.isSubmitted ?
<form onSubmit={handleSubmit(onSubmit)}>
<fieldset>
<legend>Contact</legend>
<div>
<div>
<div>
<label htmlFor="fullname">Name</label>
<input id="fullname" name="fullname" placeholder="Type your name" className={errors.fullname ? "c-form__textbox error" : "c-form__textbox"} {...register("fullname", { required: true })} />
{errors.fullname && <div className="validation--error"><p>Please enter your name</p></div>}
</div>
</div>
<div>
<div>
<label htmlFor="email">Email</label>
<input id="email" name="email" placeholder="Email" className={errors.contactemail ? "c-form__textbox error" : "c-form__textbox"} {...register("email", { required: true, pattern: /^[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,4}$/ })} />
{errors.email && <div className="validation--error"><p>Please enter a valid email</p></div>}
</div>
</div>
<div>
<div>
<label htmlFor="contactmessage">Message</label>
<textarea id="contactmessage" name="contactmessage" placeholder="Message" className={errors.contactmessage ? "c-form__textarea error" : "c-form__textarea"} {...register("contactmessage", { required: true })}></textarea>
{errors.contactmessage && <div className="validation--error"><p>Please enter your message</p></div>}
</div>
</div>
<div>
<input type="submit" value="Submit" />
</div>
</div>
</fieldset>
{state.isError ? <p>Unfortunately, your submission could not be sent. Please try again later.</p> : null}
</form>
: <p>Thank you for your message. I will be in touch shortly.</p>}
</div>
);
}
The form uses FormData to store all hidden field and text input values. You'll notice the exact same naming conventions are used as we have seen when viewing the source code of the ActiveCampaign form.
All fields need to be filled in and a package called react-hook-form is used to perform validation and output error messages for any field that is left empty. If an error is encountered on form submission, an error message will be displayed, otherwise, the form is replaced with a success message.
Demo
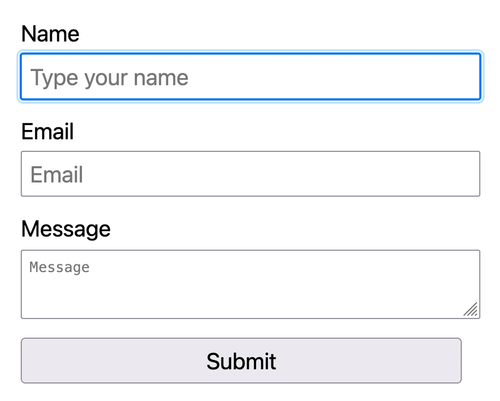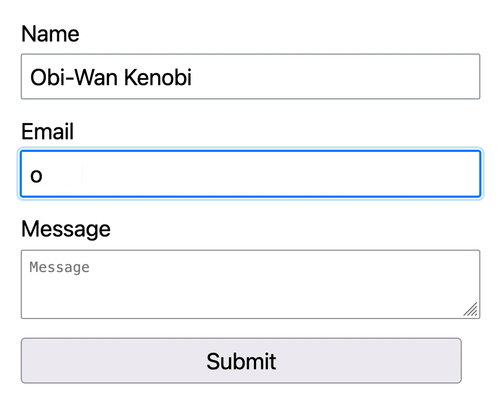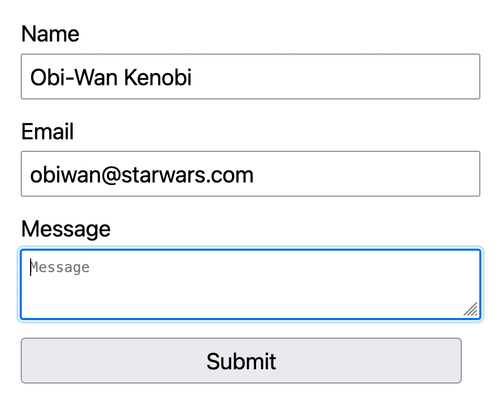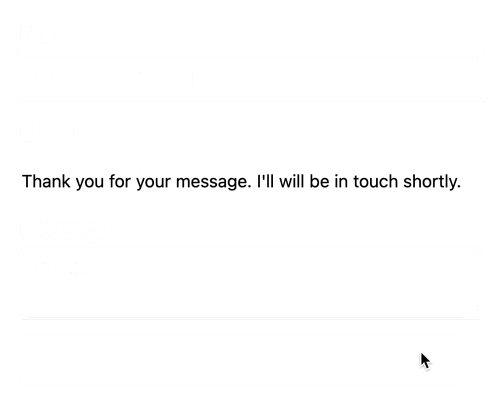
We will see Obi-Wan Kenobi's entry added to ActiveCampaign's Contact list for our test submission.
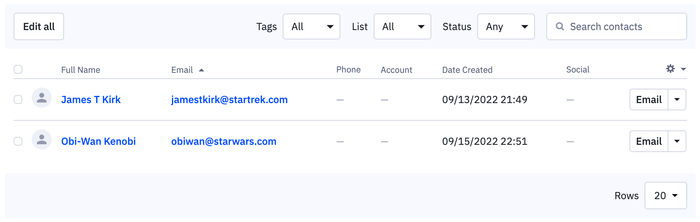
Conclusion
In this post, we have demonstrated how a form is created within ActiveCampaign and understand the key areas of what the created form consists of in order to develop a custom implementation using GatsbyJS or React.
Now all I need to do is work on the front-end HTML markup and add this functionality to my own Contact page.












