Being a web developer I am trying to become savvier when it comes to factoring additional SEO practices, which is generally considered (in my view) compulsory.
Ever since Google updated its Search Console (formally known as Webmaster Tools), it has opened my eyes to how my site is performing in greater detail, especially the pages Google deems as links not worthy for indexing. I started becoming more aware of this last August, when I wrote a post about attempting to reduce the number "Crawled - Currently not indexed" pages of my site. Through trial and error managed to find a way to reduce the excluded number of page links.
The area I have now become fixated on is the sheer number of pages being classed as "Duplicate without user-selected canonical". Google describes these pages as:
This page has duplicates, none of which is marked canonical. We think this page is not the canonical one. You should explicitly mark the canonical for this page. Inspecting this URL should show the Google-selected canonical URL.
In simplistic terms, Google has detected there are pages that can be accessed by different URL's with either same or similar content. In my case, this is the result of many years of unintentional neglect whilst migrating my site through different platforms and URL structures during the infancy of my online presence.
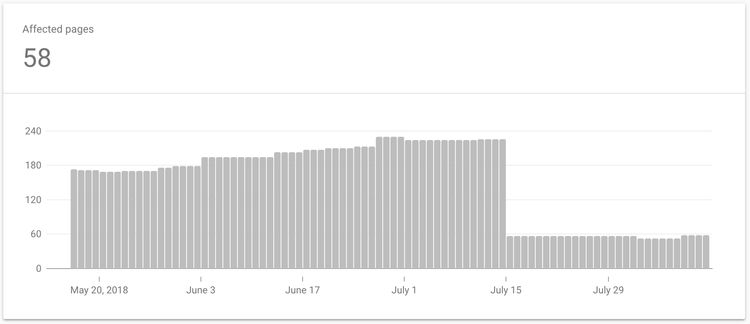
Google Search Console has marked around 240 links as duplicates due to the following two reasons:
- Pages can be accessed with or without a ".aspx" extension.
- Paginated content.
I was surprised to see paginated content was classed as duplicate content, as I was always under the impression that this would never be the case. After all, the listed content is different and I have ensured that the page titles are different for when content is filtered by either category or tag. However, if a site consists of duplicate or similar content, it is considered a negative in the eyes of a search engine.
Two weeks ago I added canonical tagging across my site, as I was intrigued to see if there would be any considerable change towards how Google crawls my site. Would it make my site easier to crawl and aid Google in understanding the page structure?
Surprising Outcome
I think I was quite naive about how my Search Console Coverage statistics would shift post cononicalisation. I was just expecting the number of pages classed as "Duplicate without user-selected canonical" to decrease, which was the case. I wasn't expecting anything more. On further investigation, it was interesting to see an overall positive change across all other coverage areas.
Here's the full breakdown:
- Duplicate without user-selected canonical: Reduced by 10 pages
- Crawled - Currently not indexed: Reduced by 65 pages
- Crawl anomaly: Reduced by 20 pages
- Valid : Increased by 60 pages
The change in figures may not look that impressive, but we have to remember this report is based only on two weeks after implementing canonical tags. All positives so far and I'm expecting to see further improvements over the coming weeks.
Conclusion
Canonical markup can often be overlooked, both in its implementation and importance when it comes to SEO. After all, I still see sites that don't use them as the emphasis is placed on other areas that require more effort to ensure it meets Google's search criteria, such as building for mobile, structured data and performance. So it's understandable why canonical tags could be missed.
If you are in a similar position to me, where you are adding canonical markup to an existing site, it's really important to spend the time to set the original source page URL correctly the first time as the incorrect implementation can lead to issues.
Even though my Search Console stats have improved, the jury's still out to whether this translates to better site visibility across search engines. But anything that helps search engines and visitors understand your content source can only be beneficial.