At the end of 2017, I made a new years resolution: make more of an active effort to blog. Not only within my own website but to also do a little writing elsewhere to try something a little different. Generally, I fail to stick by my resolutions, this year was different and I have to give myself a pat on the back for the number of posts I managed to crank out over the year.
Even though I have blogged for over 11 years, I found setting myself setting a new years resolution to write more has increased my overall confidence in writing as well as enjoyment. I now find myself using writing as a release to organise my thought process, especially when trying to grasp new learning concepts. If what I write helps others, that's a bonus!
I highly recommend everyone to write!
Popular Posts of The Year
This year I have written 24 posts (including this one), ranging from technical and personal entries. I've delved into my Google Analytics and picked a handful of gems where I believe in my own small way have made an impact:
One of the most common crawl message everyone experiences when viewing their Search Console. There isn't an exact science to resolving this issue, so decided to investigate a way to reduce the number of crawl errors by looking into the type of links Google was ignoring and submitting these links into a new sitemap.
PaginationHelper class that renders numbered pagination that can easily be reused across any list of data when called inside a controller.
A nice helper method to easily allow for partial views to be rendered as string outside controller context in .NET Core.
A Powershell script to clear out old IIS logs that can be run manually or on a schedule.
Originally written for Syndicut's Medium channel, I write about my experiences using a headless CMS from past to present - Kentico Cloud. When posted to Medium, I was very happy with the responses from the Kentico community as well as the stats. Since posting, it one of the most active viewed posts on the Syndicut Medium channel.
This year I started learning and developing my first app using React Native. I have much more to write about the subject next year. This post detailed a bug (now rectified in the new version of React Native framework) when an API endpoint returns an empty response.
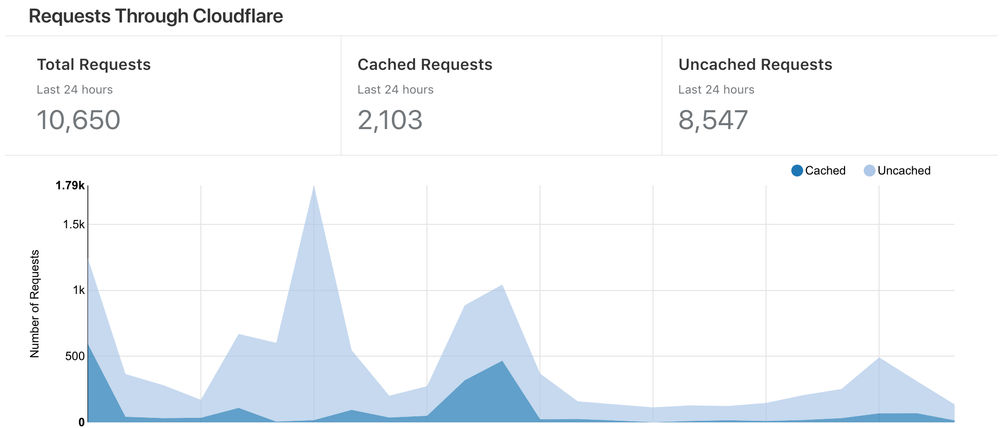
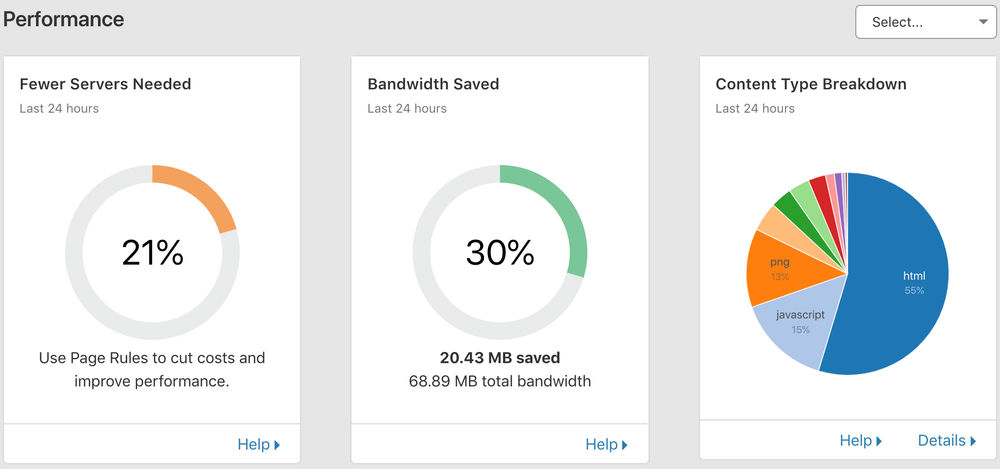
I've been using Cloudflare's CDN infrastructure to improve load times and security for my website. I developed a C# method that uses Cloudflare's API to clear cache from the CDN at code level.
A completely out of the ordinary post - a post about travel! Writing about my time at Melia Bali is the highlight to any of the posts written this year. I was testing the waters for a different writing style and hoping to produce more in a similar format. Definitely got the creative juices flowing!
Site Refresh
Throughout 11 years of owning and running this site, I have only ever refreshed the look around three times in its lifespan. It's always been a low priority in my eyes and in October I released a new look to my site. It's not going to win any prizes, but it should make my posts easier on the eye with some added flair and professionalism. I've also worked very hard on implementing additional optimisations for SEO purposes.
Guest Writing
I made a conscious choice this year to use other places to write outside the comfort of my own website to do some writing. When writing outside your own personal blog the stakes are higher and makes things a little more challenging as you need to cater your content to a potentially different audience.
Out of the 24 posts I've written this year, 4 of them are what I categorised as "Guest Writing"... I need to come up with a better name.
Currently, I've written a post for C# Corner and the rest on Syndicut's Medium channel. This is an area I wish to grow in. I am actually in the middle of writing a piece (nothing to do with coding and more to do with fiction) for film/entertainment website Den of Geek. What attracted me to write for Den of Geek is not just their content, but their award-winning mental health campaign.
Statistics
When comparing my statistics to date over the year to last year, I have an increase in 25% in page views and users. Bounce rate I still need to work on - currently decreased by 4%. Google Search Console statistics are looking promising - average page position has improved by 5 pages and total clicks increased by 110%.
Syndicut
2018 will mark eight and a half years working at Syndicut and this year like always has been filled with many challenging and exciting projects. If it wasn't for the diverse range of projects, which required me to do some interesting research, I don't think this blog would be filled with the content it has today. It's been a year filled with headless CMS's, consulting, blog writing, e-commerce, Alexa, ASP.NET Core, Kentico 12 and more!
Bring On 2019!
Bring on 2019 and some key areas I wish to focus and grow in...
Public Speaking
If I had to choose one thing I need to do next year, is to present a worthy technical subject for one of .NET Oxford's Lightning Talks. For those who do not know .NET Oxford - it's a great meetup for .NET Developers discussing anything and everything in the Microsoft Development industry.
Every so often, they have lightning talks where developers can present their own subject matter. Even though I am familiar with presenting in front of clients through work, a technical conference is a completely different kettle of fish! After all, what you present needs to be useful to the people in the same industry.
There was something Jon Skeet said in one of the .NET Oxford meetups in October that resonated with me. He said something along the lines of: everyone should do a public talk and take part in sharing knowledge. Now if Jon Skeet says that, who am I to argue!? I just need to have a ponder on the subject I wish to talk about.
Consulting
I would like to do some more consulting work. Syndicut has given me the opportunity to do that, providing our ongoing expertise to help one of our clients in adopting headless CMS (Kentico Cloud) into their current infrastructure. It was a surprise to me how much I've enjoyed consulting and this is an area I wish to continue to grow in addition to what I do best - code!
Continue To Be Social Network Hermit
I found it refreshing not to invest too much time (if any) in getting distracted by other people's lives on social networking sites like Facebook and Instagram. I will continue the process investing time in my own life and as a result feeling much more productive in doing so.
I do not claim martyr in this area, afterall I am an active Twitter user and this will not change. For me, Twitter houses a collection of ideas from users in an industry I am very passionate about.
Other Bits
I really need a coffee table and desk! It's been a long time coming. Maybe 2019 will be the year I actually get one! :-)
Surinder signing off!